This month’s Patch Tuesday stands out for its sheer volume. Microsoft addressed over 200 CVEs in its products and components, contributing to a combined total exceeding 500 when including Chromium and third-party fixes. This represents the largest single-month release in recent years.
The numbers reflect more than just accumulated technical debt. They illustrate how the discovery process itself has accelerated. Tools capable of systematically analyzing large codebases now surface issues at a pace that traditional manual auditing cannot match. Many of these flaws likely existed undetected for years; the patches address them now because the detection capability caught up.
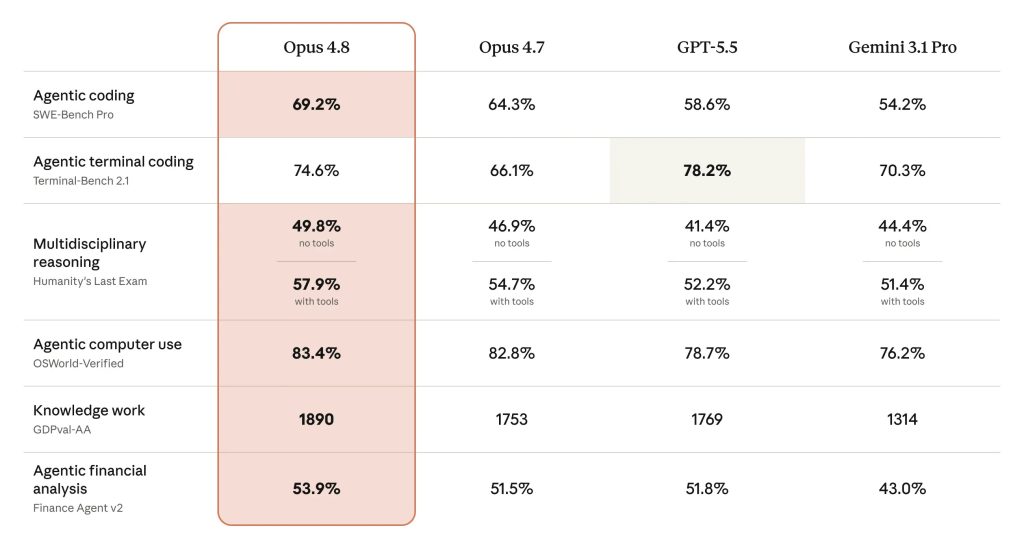
This situation mirrors Anthropic’s recent release of Claude Fable 5. Anthropic developed a highly capable underlying model but deployed a public version (Fable) with layered classifiers. These classifiers detect and reroute queries related to cybersecurity, biology, chemistry, or related high-risk areas to a less specialized fallback model. The full-capability version remains restricted to vetted users, such as qualified defenders and infrastructure operators.
The approach acknowledges a core asymmetry: the same capabilities that strengthen defense—finding subtle bugs, reasoning through complex systems, generating test cases—can also accelerate offensive work if broadly available. By gating full access, the deployment attempts to tilt the balance toward those operating under structured accountability rather than unrestricted experimentation.
Patch Tuesday embodies the defensive side of this dynamic. Organizations receive the patches because discovery tools, including advanced AI systems, identified the issues. Yet the volume creates its own pressures: enterprises must prioritize, test, and deploy at scale while facing tight windows before exploitation attempts increase. The same wave of discovery that produces these patches also shortens the effective time defenders have to respond.
In AI security contexts, this creates recurring questions. Models that excel at code analysis improve patching velocity and can support red-team exercises or hardening efforts. However, without controls, they lower barriers for those seeking to weaponize findings. Fable’s design—full power for limited trusted parties, constrained access for the public—represents one operational response to that tension. It prioritizes measurable risk reduction over uniform openness.
For security practitioners, the takeaway remains practical. Record Patch Tuesdays are not anomalies but signals of an environment where vulnerability surface area meets improved detection. Prioritization frameworks, rapid testing pipelines, and segmented deployment strategies become essential. The tools driving discovery will continue advancing; the discipline required to apply the resulting patches must advance in parallel.
The parallel between massive CVE batches and controlled model releases highlights the same underlying reality: capability growth demands deliberate boundaries if the net outcome is to favor secure systems over widespread exploitation.