
image source: Anthropic
Anthropic unveiled Claude Opus 4.8 on May 28, 2026, delivering a targeted upgrade to its flagship Opus-class model. The new release emphasizes sharper judgment, greater honesty, and improved autonomy for long-running tasks, positioning it as a more dependable collaborator for complex coding, agentic workflows, and professional knowledge work. It launches at the same pricing as its predecessor.
Benchmark Dominance Across Key Frontiers
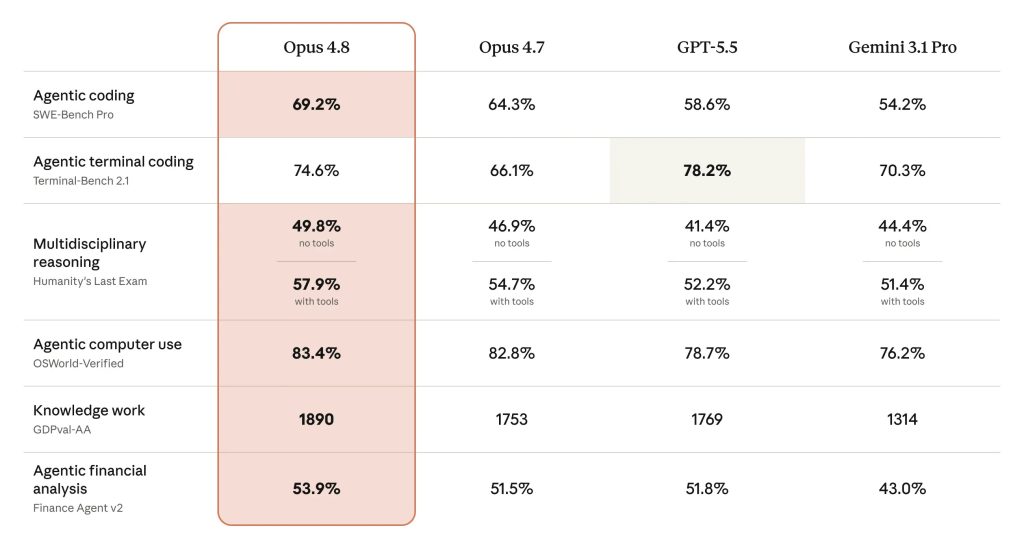
Evaluations show Opus 4.8 claiming the top spot on several leaderboards, particularly in areas that matter for real-world deployment.
- SWE-Bench Pro (harder agentic coding benchmark): 69.2%, a nearly 5-point jump over Opus 4.7 and more than 10 points ahead of leading competitors
- SWE-Bench Verified: 88.6%
- Artificial Analysis Intelligence Index: 61.4, placing it at the very top
- GDPval-AA (agentic knowledge work): Significant Elo gains, implying strong head-to-head performance with greater efficiency
- Super-Agent Benchmark: The only model to complete every case end-to-end
- Strong gains on Terminal-Bench and other agentic/tool-use tests
The model also shows meaningful improvements in honesty and self-assessment. It is reportedly far less likely to leave unreported flaws in its own code and demonstrates better recall with stable precision.
New Capabilities and Features
Beyond raw benchmarks, Opus 4.8 ships with practical enhancements:
- Effort Controls on claude.ai: Users can now dial reasoning effort from low to max for better trade-offs between speed and depth
- Dynamic Workflows in Claude Code: The model can spawn and manage hundreds of parallel sub-agents for massive codebase-scale projects
- Cheaper Fast Mode: Significantly more affordable while delivering much higher speed
- 1M token context window remains, with refinements for long-horizon autonomy
Pricing stays consistent at the same rate as Opus 4.7 for standard mode. Fast mode is more accessible but remains premium.
How It Stacks Up
Opus 4.8 represents a modest but tangible step forward rather than a revolutionary leap. It excels in greenfield projects, one-shot features, long-running agentic tasks, and reliability where consistency matters most. It trails slightly in some terminal/CLI scenarios but offers excellent overall performance for complex work.
Early user reports are largely positive for coding and complex reasoning, with some noting variability depending on configuration and effort level.
Why It Matters
In a rapidly advancing AI landscape, Opus 4.8 strengthens Anthropic’s position in the high-end agentic and coding segments. Its focus on reliability, reduced hallucinations in self-evaluation, and better long-horizon performance could accelerate adoption in enterprise software engineering, legal analysis, research, and autonomous AI systems.
The model is available now across claude.ai, Claude Code, the Anthropic API, AWS Bedrock, and partners like GitHub Copilot.
For AI teams chasing frontier performance in agentic workflows, Opus 4.8 is worth testing immediately—especially if reliability and coding depth are your top priorities.